복제
복제? 네트워크로 연결된 여러 장비에 동일한 데이터의 복사본을 유지한다.
- 지연 시간 감소 : 지리적으로 데이터를 가까운 위치에 둠으로써 지연 시간을 줄인다.
- 고가용성 : 일부 시스템 장애에도 지속적으로 서비스를 제공할 수 있다.
- 높은 처리량 : Read 쿼리를 수행하는 장비의 수를 늘려서 Read 처리량을 늘린다.
* 데이터가 아주 작아 각 장비에 전체 데이터셋의 복사본을 보유할 수 있다고 가정한다. - 데이터셋이 너무 커서 파티셔닝이 필요한 경우는 6장에서 다룬다.
복제 알고리즘
복제 중인 데이터가 그대로 있으면 슥 옮기면 된다. 하지만 데이터가 변경되는 중에는 복제가 쉽지 않다.
대부분의 분산 데이터베이스는 아래 세 가지 복제 알고리즘 중 하나를 사용한다.
-동기식/비동기식
-잘못된 복제본 처리
-최종적 일괏넝? 163 복제지연문제
1. Single-leader
2. Multi-leader
3. Leaderless
리더와 팔로워
1. Leader-based Replication
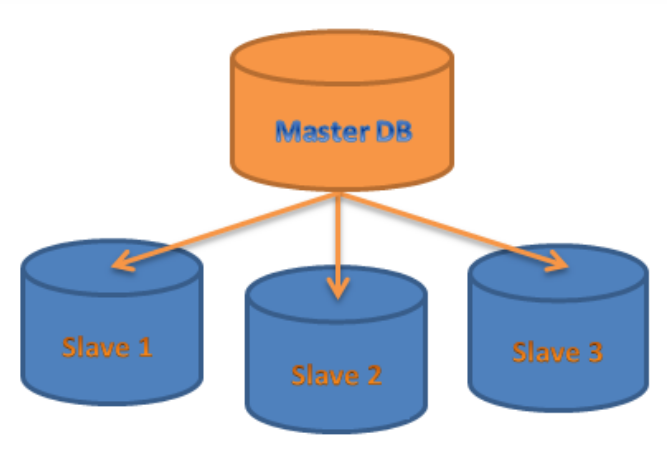
가장 일반적인 복제로, 복제 서버 중 하나를 Leader로 선정, 나머지를 Follwer로 선정한다.
- Leader(= Master, Primary) : Read and write
- Follwer(=Read Replica, Secondary, Hot standby) : Only read
쓰기 요청 처리 (Figure. 5-1)
1. 클라이언트는 리더에게 Write 요청을 보낸다.
2. 리더는 로컬 저장소에 새로운 데이터를 기록한다.
3. 리더는 데이터 변경을 복제 로그(=변경 스트림)으로 기록하고, 이를 팔로워에게 전송한다.
4. 팔로워는 리더로부터 받은 로그를 이용하여 로컬 저장소에 복사본을 갱신한다.

동기식 / 비동기식 복제
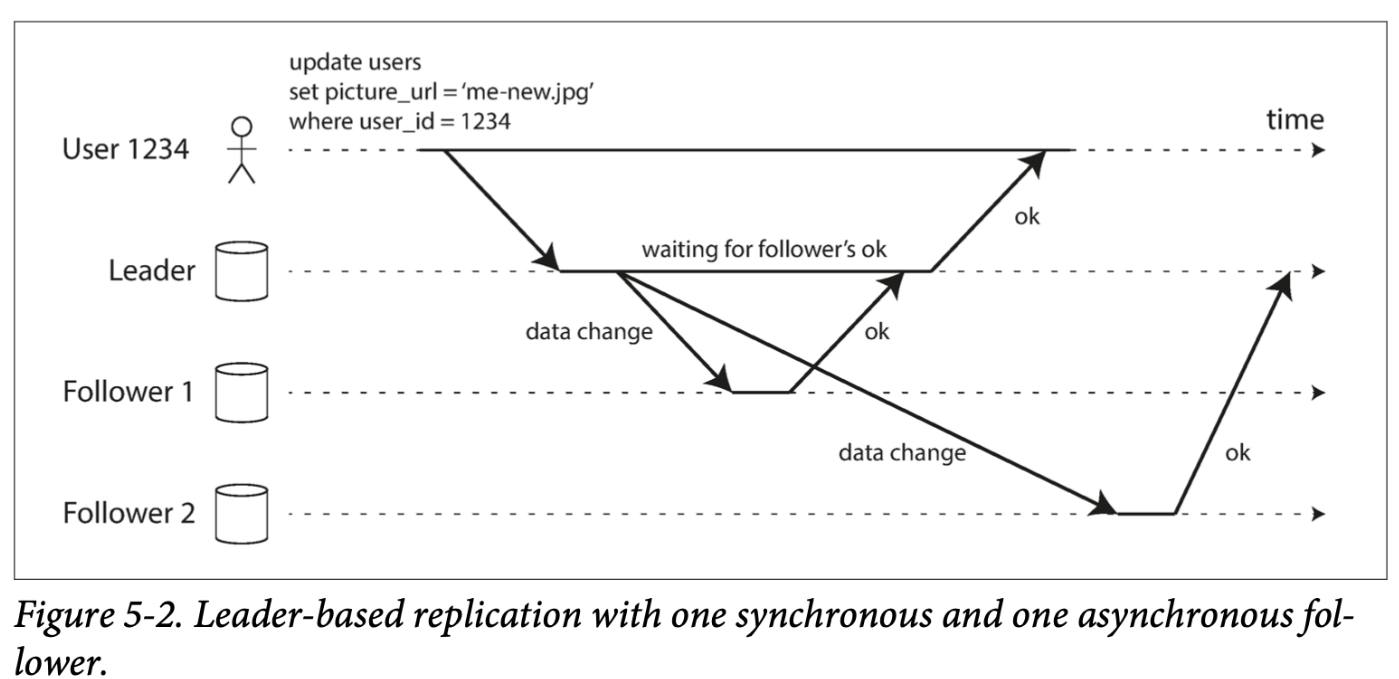
갱신 요청 처리(Figure. 5-2)
1. 클라이언트는 리더에게 갱신 요청을 보낸다.
2. 리더는 클라이언트의 요청을 수행하고, 팔로워1, 2에게 데이터 변경을 요청한다.
3. 팔로워 1, 2는 요청 수행 후, 리더에게 완료 메시지를 전달한다.
- 팔로워 1의 완료 메시지를 받은 리더는 팔로워 2의 완료 메시지를 받지 못했지만 곧장 클라이언트에게 요청이 완료되었음을 알린다. ( 팔로워 1은 동기식 복제, 팔로워 2는 비동기식 복제 )
동기식 복제
- 팔로워가 항상 최신 복제본을 가지고 있음을 보장한다. 때문에 갑작스런 리더 장애에도 팔로워가 대체될 수 있다.
- 팔로워가 사용 불가능한 상태인 경우, 요청이 완료되지 못한다. 이러한 경우, 리더는 모든 Write 요청을 차단해야 하며, 팔로워가 사용 가능한 상태가 될 때 까지 요청이 차단된다.
- 임의의 한 노드의 장애가 전체 시스템의 장애로 이어지기 때문에 모든 팔로워를 동기식으로 구성하는 것은 비현실적이다.
반동기식 복제
- 팔로워 하나를 동기식, 이 외 팔로워를 비동기식으로 구성한다.
- 적어도 두 노드(리더와 하나의 동기 팔로워)는 최신 복제본을 가지고 있음을 보장한다.
비동기식 복제
- 보통 리더 기반 족제 구성 방법이다.
- 리더에 Write 요청이 왔으나 팔로워로 데이터 변경을 전달하기 전에 리더 장애가 발생하여 리더 데이터를 복구할 수 없는 경우, 아직 복제되지 않은 Write 요청은 모두 유실된다.
- 모든 팔로워가 사용 불가능 상태가 되더라도 리더는 요청을 계속 처리할 수 있다.
새로운 팔로워 설정
새로운 팔로워 설정
복제 서버 수를 늘리거나 장애 노드 대처를 위해 새로운 팔로워를 추가해야 하는 경우가 있따.
1. 리더의 스냅샷을 일정 시점에 가져온다.
2. 스냅샷을 새로운 팔로워 노드에 복사한다.
3. 팔로워는 리더에 연결해 스냡샷 이후 발생한 모든 데이터변경을 요청한다. 이때 로그 위치를 가지고 데이터 변경을 요청한다. (Postgresql : Log sequence number, MySQL : binlog 등)
4. 팔로워가 스냅샷 이후의 변경을 모두 처리하고, 리더에 발생하는 데이터 변경 스트림을 이어 처리한다.
팔로워 장애
리더 - 팔로워 간 일시적으로 네트워크가 중돤되는 경우
1. 팔로워가 보관하고 있는 로그에서 결함 발생 전 마지막 트랜잭션을 알아낸다.
2. 팔로워는 리더에 연결해 결함이 발생한 이후의 데이터 변경을 요청한다.
3. 팔로워는 리더에 발생하는 데이터 변경 스트림을 이어 처리한다.
리더 장애 (MariaDB 장애 복구편 참고)
1. 리더 장애 인지
- 대부분의 시스템에서 타임아웃을 사용하여 장애를 판단한다. 서로 주기적으로 메시지를 주고 받으며, 일정 시간 동안 노드가 응답하지 않는 경우, 죽은 것으로 간주한다. ( 의도적으로 중단한 경우는 타임아웃을 적용하지 않는다. )
2. 새로운 리더 선택
- 선출 과정(9장)을 통해 이뤄지거나 아장 최식 데이터 변경 사항을 가진 복제 서버를 리더로 선출한다.
3. 새로운 리더 사용을 위한 시스템 재설정
- 클라이언트는 새로운 리더에게 Wrtie 요청을 보내야 한다(213쪽 요청 라우팅에서 자세히 설명).
- 이전 리더가 다시 복구되더라도 자신이 리더임을 인식해야 한다.
리더 장애 과정을 어려움
- 비동기식 복제의 경우, 리더 결함 이전 Write 요청이 발생한 경우, 복제되지 않은 Write 작업은 폐기된다.
- 새로운 리더가 선출되었으나 이전 리더가 복구되어 리더가 중복되면서 작업이 충돌할 수 있다.
- 자동으로 증가하는 값을 Key로 사용하는 경우, 새로운 리더를 선출하였으나 해당 리더가 이전 리더보다 뒤처진 상태여서 데이터 불일치가 발생할 수 있다.
- 특정 결함 시나리오(8장)에서 두 노드가 리더로 인식하는 경우가 발생할 수 있다. (split brain) (169p 다중 리더 복제에서 다룰 예정?) 데이터 유실 또는 오염될 수 있다.
- 리더가 죽었다고 판단 가능한 적절한 타임아웃 설정이 어렵다. 너무 길면 복구까지 오랜 시간이 소요되고, 너무 짧으면 일시적인 네트워크 지연인데 불필요한 장애 복구가 이뤄질 수 있다.
복제 로그 구현
리더 기반 복제의 내부 동작 방식
1. 구문 기반 복제
리더는 Write 요청을 구문(statement)을 기록하고, 요청을 수행한 후, 팔로워에게 전송한다.
관계형 데이터베이스는 모든 Insert, Update, Delete 구문을 팔로워에게 전달하고, 팔로워는 클라이언트의 요청을 직접 받을 것 처럼 SQL 구문을 파싱하고 수행한다.
문제점
- now(), rand()과 같은 비결정적 함수 사용 시에, 복제 서버마다 다른 값을 생성할 가능성이 있다.
- 자동증가 컬럼을 사용하는 구문이나 데이터베이스에 있는 데이터에 의존(Update)하는 경우, 각 복제 서버에서 정확히 같은 순서로 실행되어야 한다.
- 부수 효과를 가진 구문(Trigger, Stored Procedure, User Defined Function)의 경우, 부수 효과가 완전히 결정적이지 않으면, 각 복제 서버에서 다른 부수 효과가 발생할 수 있다.
2. 쓰기 전 로그 배송
- 로그 구조화 저장소 엔진(SS테이블, LSM 트리)의 로그 세그먼트
- B 트리의 모든 변경은 WAL로 기록
위 두 경우 모두 Append-Only 방식으로, 완전히 동일한 로그를 이용하여 다른 노드에 복제 서버를 구축할 수 있다.
리더는 디스크에 로그를 기록하고, 팔로워에게 네트워크를 통해 로그를 전송한다.
WAL은 어떤 디스크 블록에서 어떤 바이트를 변경했는지와 같은 상세 정보를 포함한다. 때문에 리더와 팔로워의 데이터베이스의 저장소 엔진 버전을 다르게 실행할 수 없다.
3. 논리적(로우 기반) 로그 복제(MySQL BinaryLog 참고 자료 필요..)
복제 로그를 저장소 엔진(물리적인 부분)과 분리하기 위한 대안으로, 논리적 로그를 사용한다.
관계형 데이터베이스에서 논리적 로그는 대개 로우 단위로 테이블에 쓰기를 기술한 레코드 열이다.
(내용 보강 필요)
4. 트리거 기반 복제
데이터의 서브셋만 복제하거나 다른 종류의 데이터베이스로 복제하거나 충돌 해소 로직이 필요한 경우 사용한다.
트리거는 사용자 정의 애플리케이션 코드를 등록할 수 있다. 이 코드는 데이터가 변경되면(쓰기 트랜잭션) 자동 실행된다. 데이터 변경을 분리된 테이블에 로깅할 수 있으며, 외부 프로세스가 이 로그를 읽을 수 있다. (오라클용 Databus, Postgresql용 Bucardo)
복제 지연 문제
읽기 확장(Read-scaling)
- 리더 기반 복제에서 Write 요청은 리더에서만 이뤄지지만, Read 요청은 모든 복제 서버에서 처리될 수 있다.
- 대부분의 작업이 Read 요청이라면, 많은 팔로워를 두어 요청을 분산 시킬 수 있으며, 리더의 부하 또한 줄일 수 있다.
- 현실적으로 비동기식 복제인 경우에 가능하다. (동기식의 경우, 많은 팔로워 중 하나의 장애로 인해 전체 시스템이 중단될 수 있기 때문)
- 뒤처지는 팔로워가 Read 요청을 수행한 경우, 클라이언트는 지난 정보를 볼 수 있다. (복제 지연으로 인한 데이터 불일치)
- 하지만 이러한 불일치는 일시적인 상태로, 최종적으로는 데이터가 일치하게 된다. (최종적 일관성)
- '최종적'이라는 용어가 모호하다. 대개 아주 짧은 시간 데이터 불일치가 발생하지만, 네트워크 문제로 지연시간이 매우 길어질 수도 있다.
복제 지연이 발생하는 세 가지 사례를 아래에서 소개하고, 해결 방법을 설명한다..
1. 자신이 쓴 내용 읽기
쓰기 후 읽기 일관성(Read after write consistenct) (=자신의 쓰기 읽기 일관성)
웹 사이트에서 댓글을 달면, 바로 댓글을 확인할 수 있다.
하지만 비동기식 요청의 경우, 클라이언트가 리더에게 Write 요청을 보내고, 팔로우에 다시 Read 요청을 한다면 리더의 요청이 아직 팔로워에 반영되지 않아 데이터를 볼 수 없는 경우도 있을 수 있다.
이러한 경우, 쓰기 후 읽기 일관성이 필요하다.
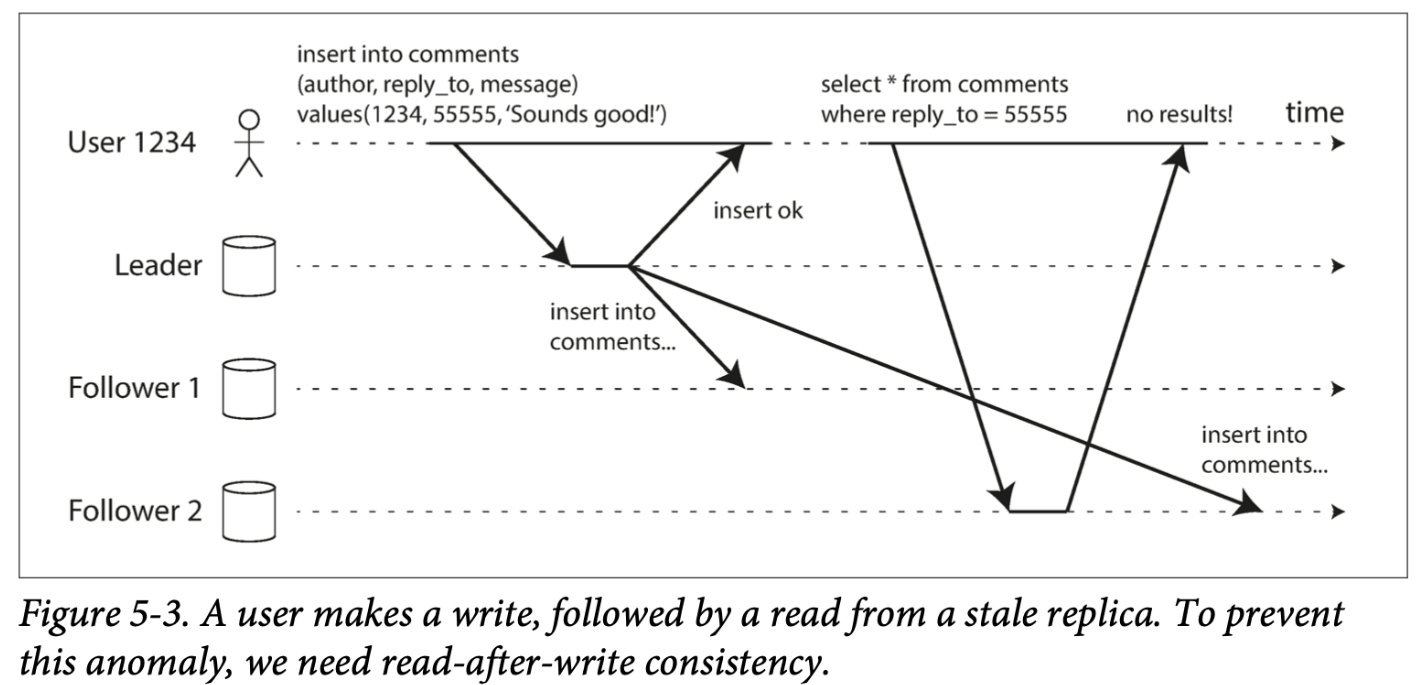
사용자는 항상 자신이 제출한 모든 갱신을 볼 수 있음을 보장한다. 다른 사용자에 대해서는 보장하지 않는다.
어떻게 구현할 것인가?(165p)
2. 단조 읽기
ㅇ
3. 일관된 순서로 읽기
ㅇ
4. 복제 지연을 위한 해결책
'IT 잡동사니' 카테고리의 다른 글
| IntelliJ Google style fomatter를 적용해보자! + 매크로 등록 (0) | 2022.05.15 |
|---|---|
| 클린코드 17장 냄새와 휴리스틱 리뷰 (0) | 2022.03.10 |
| 클린코드-시스템 (0) | 2022.02.24 |
| IntelliJ commit 메시지 한글 깨짐 (0) | 2022.01.27 |
| 윈도우! 포트 찾기 & 사용중인 포트 프로세스 죽이기! (0) | 2021.03.04 |