1. spark
Apache Spark는 빅데이터 워크로드에 주로 사용되는 오픈소스 분산 쿼리 및 처리 엔진이다. 빠른 속도로 데이터를 변환할 수 있으며, 데이터가 메모리에 있는 경우 하둡보다 100배, 디스크에 있는 경우 10배 빠르다.
데이터 양이 많고, 다양한 형태의 데이터를 분석해야 할 경우 적합하다.
하둡과 연동하여 사용할 수 있도록 설치해보자!
2. spark standalone & spark yarn cluster / client
spark는 standalone 모드와 yarn cluster, yarn client모드가 있다. 이 차이점을 살펴보자.
standalone : 다른 클러스터 매니저를 사용하지 않고, spark만으로 클러스터를 구성하는 모드
yarn cluster : 드라이버 프로세스가 cluster 내의 Master에서 실행되는 모드. 드라이버가 yarn컨테이너에서 동작하기 때문에 driver 장애가 발생할 경우 다른 노드에서 드라이버 재실행
yarn client : 드라이버 프로세스가 클러스터 외부 서버에서 실행되는 모드.
*참고 : https://www.learningjournal.guru/article/apache-spark/apache-spark-internals/
*드라이버 : 프로그램의 main()이 실행되는 프로세스
*yarn이전에는 하둡 클러스터의 리소스 상태를 맵리듀스의 JobTracker가 수행하였다. 이 기능을 yarn이 수행하도록 하여 다른 서비스와도 리소스 공유가 가능하다.
3. spark 설치하기
1) 다운로드
원하는 버전을 다운 받는다.
나는 2.3.2버전을 다운받았다.
아래 페이지에 가면 다양한 spark 다운로드 타입이 있는데, 나는 spark-2.3.2-bin-without-hadoop.tgz 를 다운받았다.
이미 설치된 하둡과 자원을 관리하는 yarn위에 스파크를 올릴 생각이기 때문이다.
일치하는 하둡 버전이 있다면 spark-2.3.2-bin-hadoop2.6.tgz 요런 파일을 다운받으면 되고, 나는 일치하는 하둡 버전이 없어 without-hadoop으로 다운받고, 따로 설정해주었다.
archive.apache.org/dist/spark/spark-2.3.2/
Index of /dist/spark/spark-2.3.2
archive.apache.org
2) 설정하기
a. 환경변수 추가
하둡관련 변수는 이전 시간에 설치하며 설정한 내용이고, 새롭게 spark관련 설정을 추가해주었다.
spark_home 위치와 yarn 설정 디렉토리를 잡아준다. yarn설정은 하둡을 설치하며 설정해주었기 때문에 하둡 설정파일이 저장된 디렉토리로 잡아주었다.
vi ~/.bashrc
#home
export HOME=/home/hadoopuser
$java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
#pdsh
export PDSH_RCMD_TYPE=ssh
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
#spark
export SPARK_HOME=/usr/local/spark
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin
b. spark-env.sh 설정
$SPARK_HOME/conf/spark-env.sh.template는 샘플이다. 이것을 복사하여 설정파일로 쓴다.
>> cp spark-env.sh.template spark-env.sh
다음으로, 나는 하둡이 포함되지 않은 설치 파일(without-hadoop)을 설치했기 때문에 이미 설치되어 있던 나의 하둡 classpath를 설정해준다.
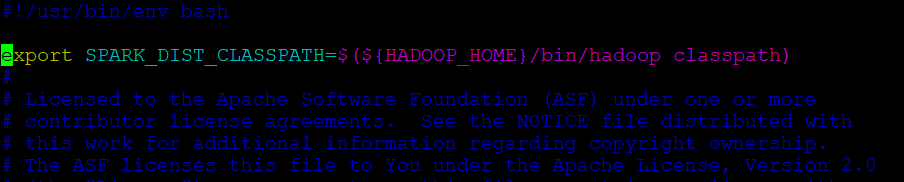
spark-env.sh을 열어 아래 내용을 추가한다.
export SPARK_DIST_CLASSPATH=$(${HADOOP_HOME}/bin/hadoop classpath)vi spark-env.sh
3) spark-shell 실행하기
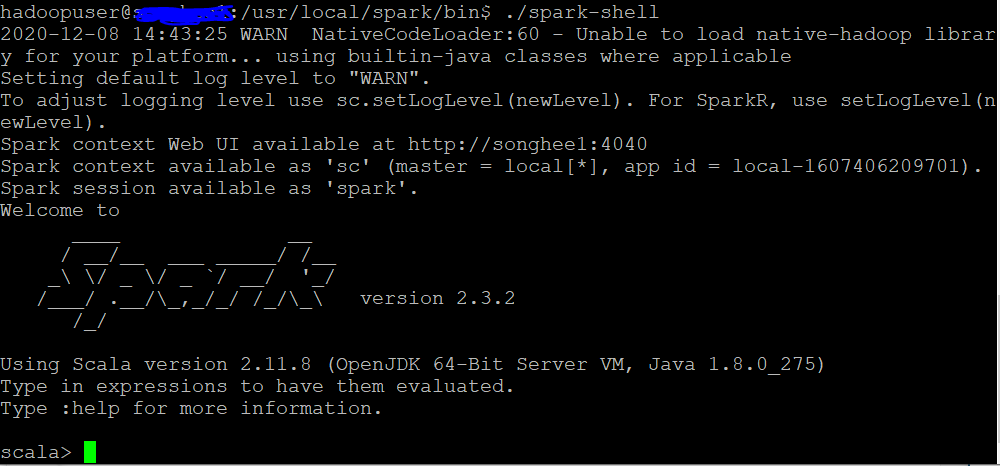
$SPARK_HOME/bin/ 아래 spark-shell을 실행한다.
아래와 같이 나오면 정상적으로 실행된 것!
4) spark 서비스 실행하기
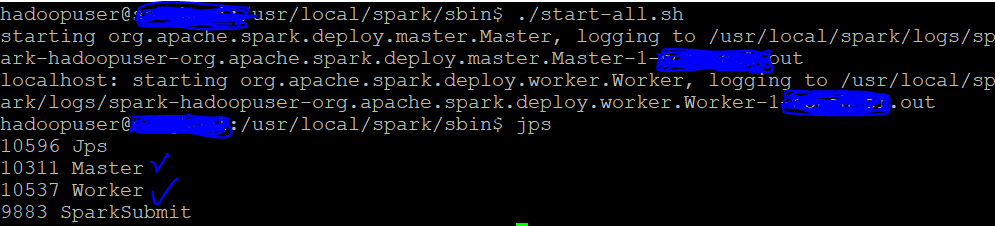
$SPARK_HOME/sbin/ 아래 start-all.sh을 실행한다.
그리고 jps를 이용하여 실행중인 자바 프로세스를 확인하면, master와 worker가 실행된 것을 확인할 수 있다.
5) web ui를 통해 확인하기
a. spark web ui
ip:8080
워커, 어플리케이션 등 확인 가능
b. hadoop web ui
ip:8088
cluster-applications에 실행 어플리케이션 확인 가능
4. 참고자료
www.popit.kr/what-is-hadoop-yarn/
YARN 무엇에 쓰는 물건인고? | Popit
Hadoop 을 처음 접하시는 분들은 HDFS에 대해서는 쉽게 이해하지만 YARN에 대해서는 개념을 잡기 어려워하시는 분들이 있습니다. 그 이유는 Hadoop하면 MapReduce를 많이 떠 올리시는데 MapReduce 따로 YARN
www.popit.kr
[Spark] Cluster 모드 vs Client 모드
스파크 드라이버(driver) 란, 프로그램의 main() 메소드가 실행되는 프로세스임. 드라이버는 Spark Context 를 생성하고 RDD를 만들고 transformation , action 등을 실행하는 사용자 코드를 실행한다. driver pro..
eyeballs.tistory.com
*spark 샘플 예제 실행
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client --driver-memory 4g --executor-memory 2g --executor-cores 1 ~/spark/examples/jars/spark-examples*.jar 10 *spark wordcount 예제
1. hdfs에 wordcount 샘플 텍스트 파일을 생성한다.
words.txt
hello I'm --.
Word count example. 2. 로컬에서 생성한 샘플 텍스트파일을 hdfs로 copy
hadoop fs -copyFromLocal ./words.txt hdfs:/user/--3. $SPARK_HOME/bin/spark-shell 실행
아래 코드를 spark-shell에서 실행
val textFile = sc.textFile("hdfs:/user/--/words.txt")
val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile("hdfs:/user/--/result")hadoopuser@--:/usr/local/spark/bin$ ./spark-shell
2020-12-09 22:51:48 WARN NativeCodeLoader:60 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://--:4040
Spark context available as 'sc' (master = local[*], app id = local-1607521912255).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.3.2
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_275)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val textFile = sc.textFile("hdfs:/user/--/words.txt")
textFile: org.apache.spark.rdd.RDD[String] = hdfs:/user/--/words.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:25
scala> counts.saveAsTextFile("hdfs:/user/--/wordCount")4. 결과
hadoopuser@--:/usr/local/spark/bin$ hadoop fs -ls /user/--/wordCount
Found 3 items
-rw-r--r-- 2 hadoopuser supergroup 0 2020-12-09 22:53 /user/--/wordCount/_SUCCESS
-rw-r--r-- 2 hadoopuser supergroup 32 2020-12-09 22:53 /user/--/wordCount/part-00000
-rw-r--r-- 2 hadoopuser supergroup 31 2020-12-09 22:53 /user/--/wordCount/part-00001
hadoopuser@--:/usr/local/spark/bin$ hadoop fs -cat /user/--/wordCount/_SUCCESS
hadoopuser@--:/usr/local/spark/bin$ hadoop fs -cat /user/--/wordCount/part-00000
2020-12-09 22:56:26,850 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
(Word,1)
(hello,1)
(example.,1)
hadoopuser@--:/usr/local/spark/bin$ hadoop fs -cat /user/--/wordCount/part-00001
2020-12-09 22:56:37,983 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
(count,1)
(I'm,1)
(--.,1)
'Spark' 카테고리의 다른 글
| IntelliJ Spark Scala 환경 세팅하기! + Scala class가 보이지 않는 경우 해결 방법! (0) | 2021.06.24 |
|---|